3 Week 3: Correlation and Causation
In lecture and in the textbook, we have been discussing the idea of correlation. This is the idea that two things that we measure can be somehow related to one another. For example, your personal happiness, which we could try to measure say with a questionnaire, might be related to other things in your life that we could also measure, such as number of close friends, yearly salary, how much chocolate you have in your bedroom, or how many times you have said the word Nintendo in your life. Some of the relationships that we can measure are meaningful, and might reflect a causal relationship where one thing causes a change in another thing. Some of the relationships are spurious, and do not reflect a causal relationship.
In this lab we will first discuss several research design concepts related to establishing causal relationships. In the second part of the lab you will learn how to compute correlations between two variables and answer some questions about the relationships between those variables. To get started, download the lab template here (right click: save as) or from Canvas. Copy the lab template to your lab folder and double click the Lab project file (not the .Rmd) to open RStudio.
3.1 Learning goals
During this lab you will do the following:
- Discuss relationships between variables and how to establish causal relationships
- Discuss the possible meaning of correlations that you observe
- Learn how to compute and visualize Pearson’s \(r\) between two variables in R
3.2 Research methods: causality
Discuss the research methods questions about causality in your breakout room and register the answers in the R Markdown template.
3.2.1 Question 1
Take a close look at the following two examples. Each example consists of a graph showing the fluctuation of two variables and a statement suggesting how to interpret such evidence. Are these statements correct? Explain your answer.
3.2.1.1 Example 1
There is a positive causal relationship between the number of people who drowned by falling into a pool and the number of films Nicolas Cage appeared in.
.](figures/cage.png)
Figure 3.1: Relationship between number of drownings and films Nicolage Cage appeared in. Illustration by Tyler Vigen.
3.2.1.2 Example 2
There is a positive causal relationship between per capita consumption of mozzarella cheese and civil engineering doctorates awarded.
.](figures/mozerella.png)
Figure 3.2: Relationship between mozerella consumption and civil engineering doctorates. Illustration by Tyler Vigen.
3.2.2 Question 2
For both scenarios described below, identify a possible confounder (variable Z) and describe its association with variables X and Y.
- The observation that when ice cream sales go up drownings of people in swimming pools increase, led the researcher to believe that ice cream consumption increases drownings.
- The observation that there is a very strong correlation between the use of social media and symptoms of depression, led the researcher to believe that excessive use of social media causes symptoms of depression.
3.2.3 Question 3
The case below presents an empirical observation that leads to a proposition. First, you are asked to identify the problem with this proposition. Then, you must provide a solution to overcome this issue. Your proposed solution should strengthen claims of a causal relationship between variables X and Y.
Your proposed solution should satisfy the following:
- Clearly identify the source of variation in the independent variable (i.e. define groups)
- Indicate how you would use the variation in the independent variable to test against the proposed causal relationship
- There is enough variation in the independent variable (i.e. number of groups) such that the effect of interest can be identified in sufficient detail.
Case
- Observation: We observe that people who exercise their hobbies regularly tend to be happier.
- Proposition: The more one exercises his or her hobbies, the happier he or she will be.
- Problem:
- Solution:
3.2.4 Question 4
In the case from the previous question: how would you test the empirical validity of competing explanations? For example, how could you test that exercising a hobby has a stronger effect for non-retirees than it has for retirees?
3.2.5 Question 5
In the previous question, you provided solutions to ambiguously formulated claims of causal relationships, in order to strengthen their empirical validity and to be able to draw meaningful conclusions. However, meaningful conclusions should be obtained from meaningful comparisons.
According to the textbook, what does a meaningful comparison entail?
3.2.6 Question 6
According to the textbook, how can we obtain meaningful comparisons?
3.2.7 Question 7
The textbook discusses three different types of interventions (independent variables). Briefly describe what they are and provide an example of your own.
3.2.8 Question 8
Read the following two cases and decide whether or not the described experiment is internally valid. If not, identify the threat to internal validity by choosing from the options below.
- Selection bias
- Demand characteristics effect
- History effect
- Maturation effect
- Repeated testing effect
- Regression to the mean
- Differential attrition
- Non-response bias
- Experimenter bias
- Placebo effect
3.2.8.1 Case 1
It was the start of a new swim season, and the coach was already concerned about her swimmers’ lack of effort during the 20-minute dry-land portion of practice. She felt they didn’t take it seriously enough, and too often they would be talking or slacking off rather than doing the required stretches and exercises. She consulted with a sports psychologist. He suggested that she write the names of all 20 swimmers on individual slips of paper, scramble them, and then pick ten without looking. This would be used to assign swimmers to a Non-contingent Group (the first ten), who would have trainings on Monday, Wednesday and Friday, and a Contingent Group (the remainder), who would have training on Tuesday, Thursday, and Saturday. The coach thought it would be easier simply to assign the swimmers to groups on the basis of friendship, but she changed her mind after the psychologist explained the rationale for this slightly more cumbersome procedure.
The intervention was that swimmers in the Contingent Group were told that if their dry-land productivity as a group for the day was 15% better than their average in the previous week then music would be played at the following practice. The productivity of the Non-contingent Group had no bearing on the playing of music. Then, each practice day for one week, observers unobtrusively recorded the swimmers’ productive behaviors during the dry-land training portion and calculated the percentage of one-minute intervals in which all swimmers in a group were being productive. Following this intervention, the dry-land productivity of the Contingent group was found to be higher than that of the Non-Contingent group so we can conclude that making the playing of music contingent on the swimmers’ dry-land productivity resulted in an increase in that productivity.
3.2.8.2 Case 2
Psychoanalysts at two different hospitals were asked to judge the well-being of a young man being interviewed on videotape. By the flip of a coin, psychoanalysts at a publicly-funded hospital were assigned to the Normal Group and psychoanalysts at a privately-funded hospital were assigned to the Abnormal Group. In the Normal Group, the doctors were told that the young man was a job applicant; in the Abnormal Group, the doctors were told that he was a patient. The mean adjustment rating by psychoanalysts in the Normal Group was 7 out of 8 compared to a 3.5 out of 8 rating by doctors in the Abnormal Group. We can conclude that the psychoanalysts’ ratings were affected by the label used to describe the young man.
3.3 Correlations in R
In this part of the lab we will use R to explore correlations between two variables. Make sure you really follow along with the code examples given.
3.3.1 cor() for correlation
R has the cor function for computing Pearson’s \(r\) between any two variables. In fact this same function can compute other versions of correlation as well (Spearman and Kendall), but we’ll skip those here. To use the function you just need two variables with numbers in them like this:
x <- c(1,3,2,5,4,6,5,8,9)
y <- c(6,5,8,7,9,7,8,10,13)
cor(x,y)## [1] 0.765393.3.1.1 Scatterplots
Let’s take our toy example, and plot the data in a scatterplot using ggplot2. Let’s also return the correlation and print it on the scatter plot. Remember, ggplot2 wants the data in a data.frame, so we first put our x and y variables in a data frame.
library(tidyverse)
df <- data.frame(x,y)
ggplot(df, aes(x=x,y=y))+
geom_point()+
annotate("text", label= round(cor(x,y),2), x = 2, y = 12)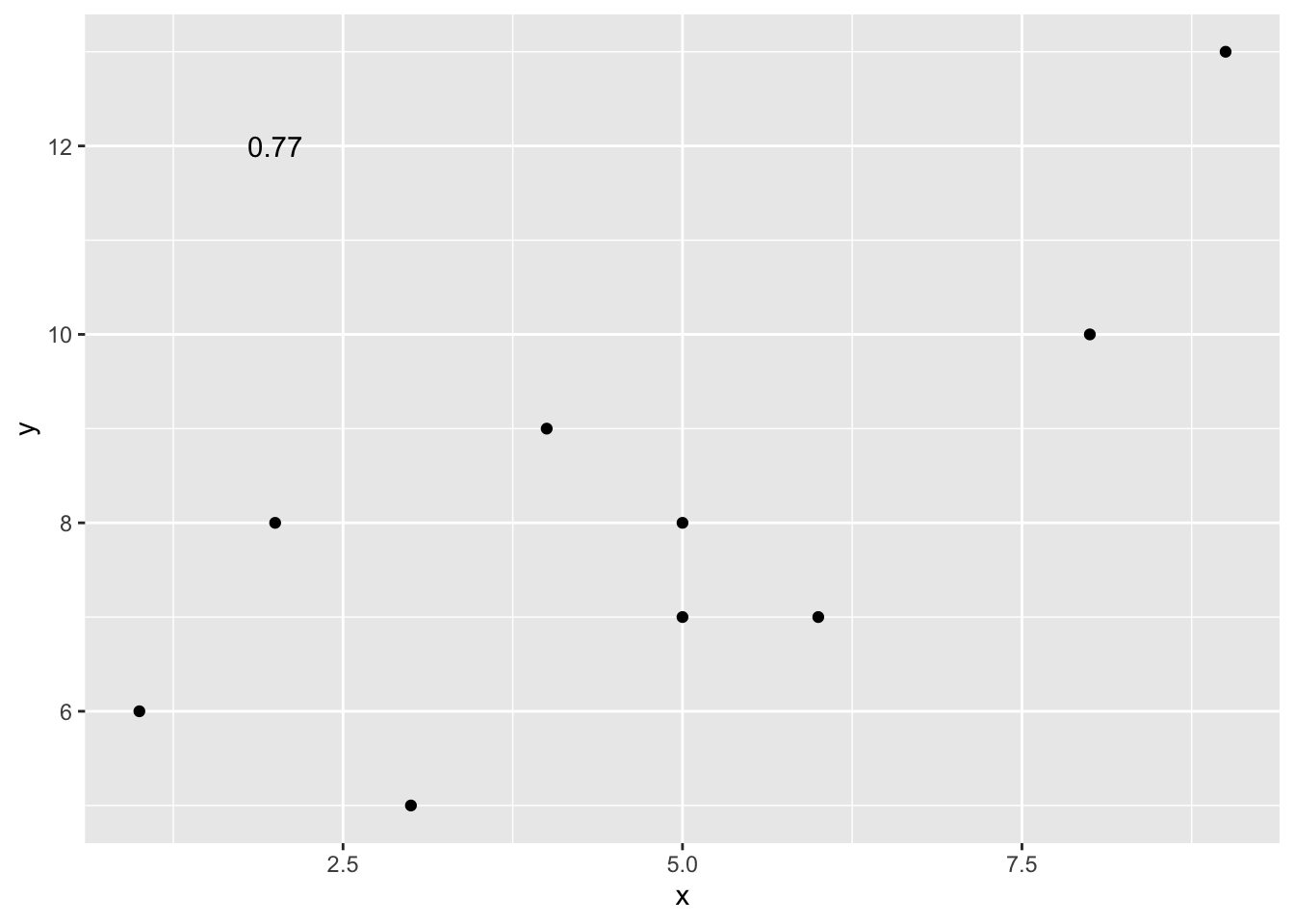
Wow, we’re moving fast here. Dissect the code above and see if you understand each step.
3.3.1.2 Lots of scatterplots
Before we move on to real data, let’s use some fake data first. Often we will have many measures of X and Y, split between a few different conditions, for example, condition A, B, C, or D. Let’s make some fake data for X and Y, for each condition A, B, C, and D.
x <- rnorm(40,0,1) # rnorm() generates a normally distributed random variable
y <- rnorm(40,0,1)
condition <-rep(c("A","B","C","D"), each=10)
df_all <- data.frame(condition, x, y)We now have a data frame with 40 (random) observations over 4 different conditions:
head(df_all)## condition x y
## 1 A 1.19955455 -0.1248665
## 2 A -1.71143716 -0.6168875
## 3 A -1.00018053 0.2541530
## 4 A 0.48148618 -1.1838535
## 5 A -0.09775389 -0.9559277
## 6 A -2.66701580 -1.2558958glimpse(df_all)## Rows: 40
## Columns: 3
## $ condition <chr> "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "B", "B",…
## $ x <dbl> 1.19955455, -1.71143716, -1.00018053, 0.48148618, -0.097753…
## $ y <dbl> -0.12486652, -0.61688746, 0.25415301, -1.18385347, -0.95592…If we were to make a scatterplot of this dataframe to look at the relationship between the x and y variable, we could do the following:
ggplot(df_all, aes(x = x, y = y))+
geom_point()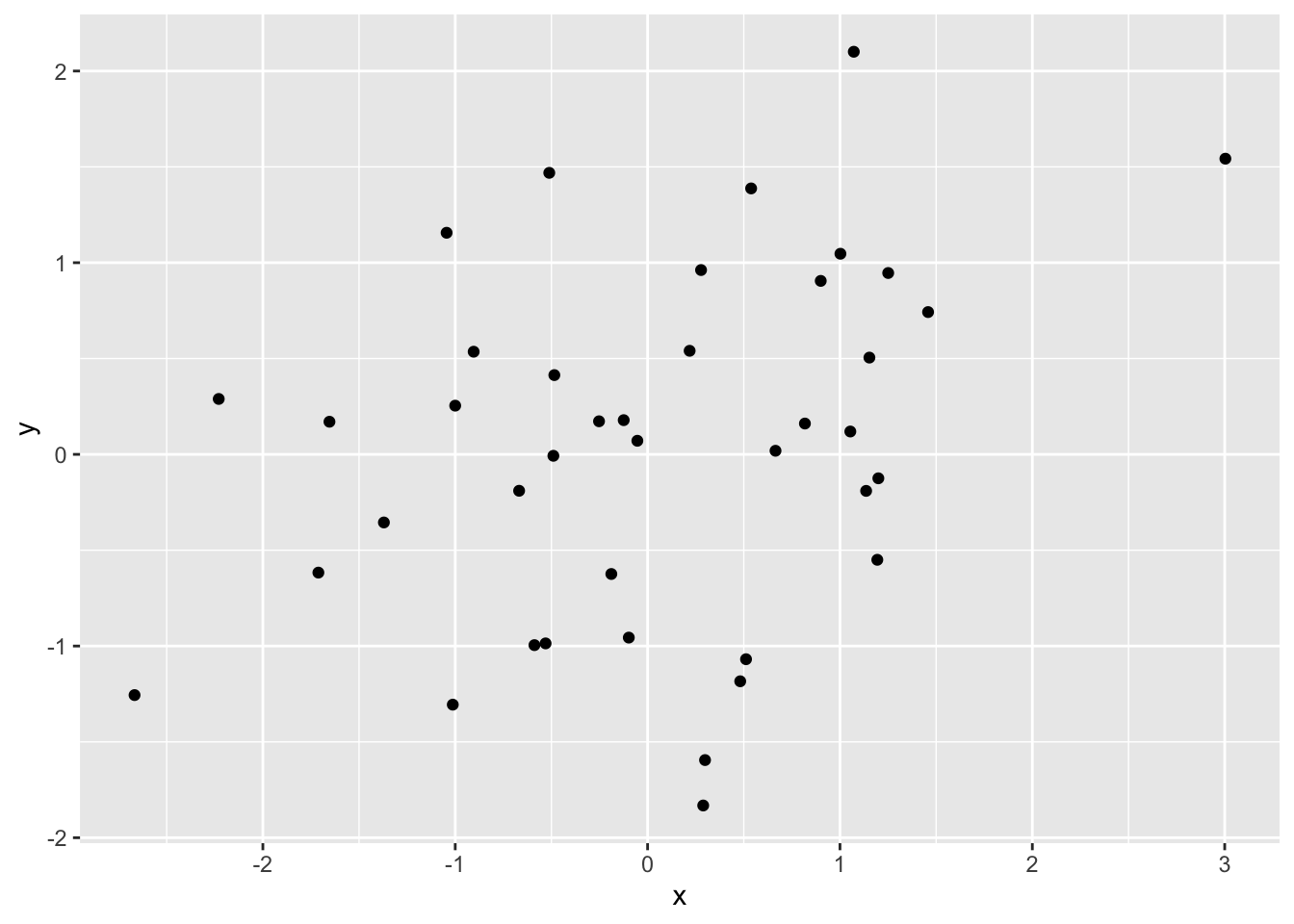
Figure 3.3: All conditions on one scatterplot
This visualizes the relationship between x and y over all conditions, but doesn’t allow us to see whether the relationship depends on the condition. If we would want to look at that, we need some way to visually discriminate the conditions on the scatterplot. You could do the following:
ggplot(df_all, aes(x = x, y = y, group = condition, color = condition))+
geom_point()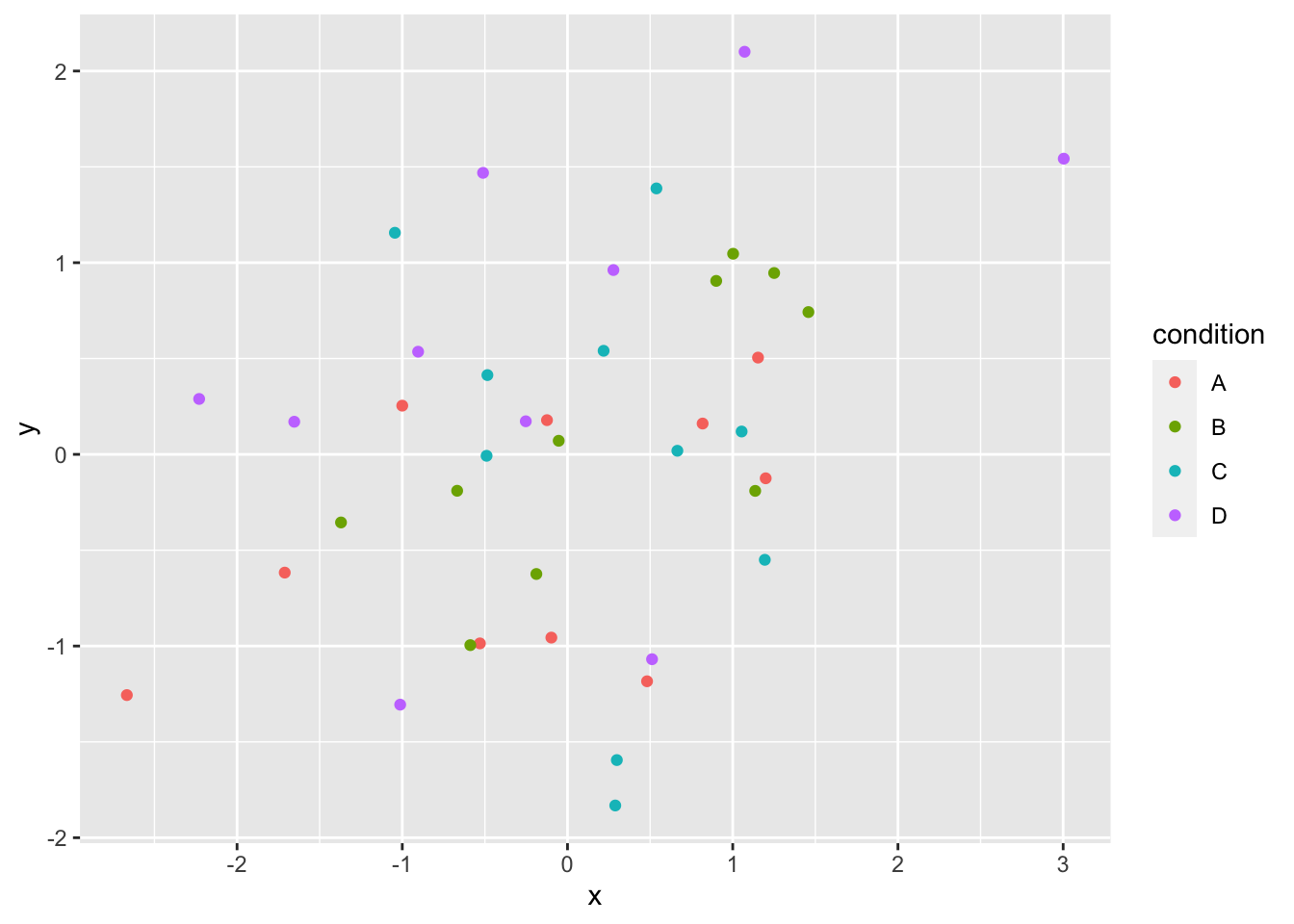
Figure 3.4: All conditions in one scatterplot, but conditions are differently colored
This is a bit better, but it’s still not easy to discriminate between conditions. Better would be to plot the conditions as four separate scatterplots and the function facet_wrap() allows us to do just that:
ggplot(df_all, aes(x = x, y = y))+
geom_point() +
facet_wrap(~condition)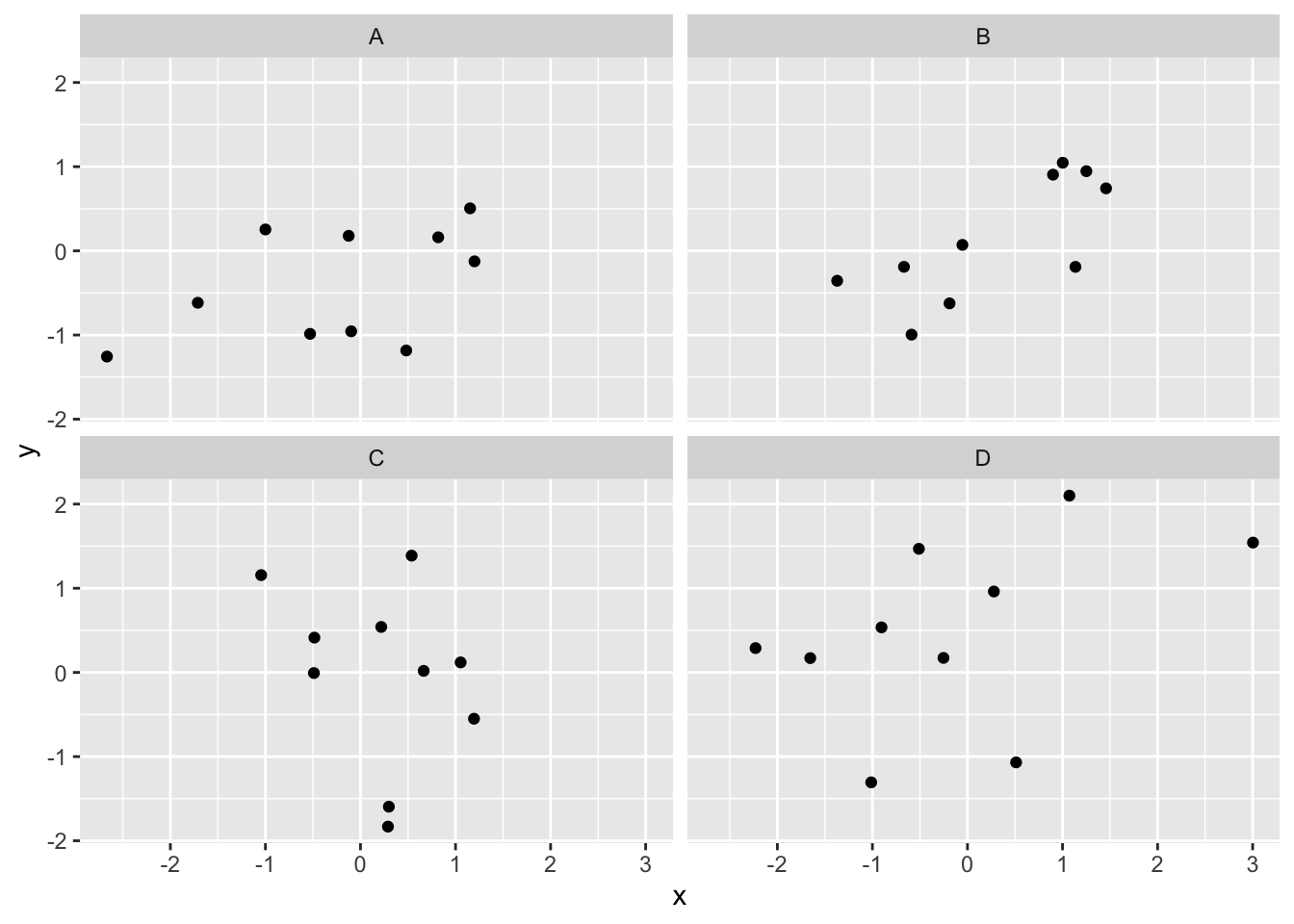
Figure 3.5: Facet wrapped scatterplot
3.3.1.3 Computing the correlations all at once
We’ve seen how we can make four graphs at once. facet_wrap() will always try to make as many graphs as there are individual conditions in the condition variable. In this case there are four, so it makes four.
What we will do now is make a table of the correlations in addition to the scatter plot. We use functions from the tidyverse library to group by conditions and calculate the correlations (summarise()) and the function kable() from the knitr library to output a nice table:
df_cor <- df_all %>%
group_by(condition) %>%
summarise(correlation = cor(x, y))
knitr::kable(df_cor,caption = "Correlation by condition.")| condition | correlation |
|---|---|
| A | 0.4917795 |
| B | 0.7524485 |
| C | -0.2953659 |
| D | 0.4449637 |
OK, we are basically ready to turn to some real data and ask if there are correlations between interesting variables… but first some exercises. Complete the following exercises in your template file.
3.3.2 Correlation exercises
- Calculate the correlation between the following two variables:
x <- c(1,2,4,8,16,32,64,NA,256,512)
y <- c(1,2,2,2,5,6,5,8,7,4)What happens in exercise 1? What is
NA? Copy/paste the code above and change it so you can still calculate the correlation betweenxandy, regardless ofNAvalues.The following plot has two problems: the value of the correlation is printed with a very large amount of decimals and at a weird position. Try to fix the problems in the code below.
x <- c(1,2,4,8,16,32,64,128,256,512)
y <- c(1,2,2,2,5,6,5,8,7,4)
corxy <- cor(x,y)
df <- data.frame(x,y)
ggplot(df, aes(x=x,y=y))+
geom_point()+
annotate("text", label = cor(x,y), x = 50, y = 2)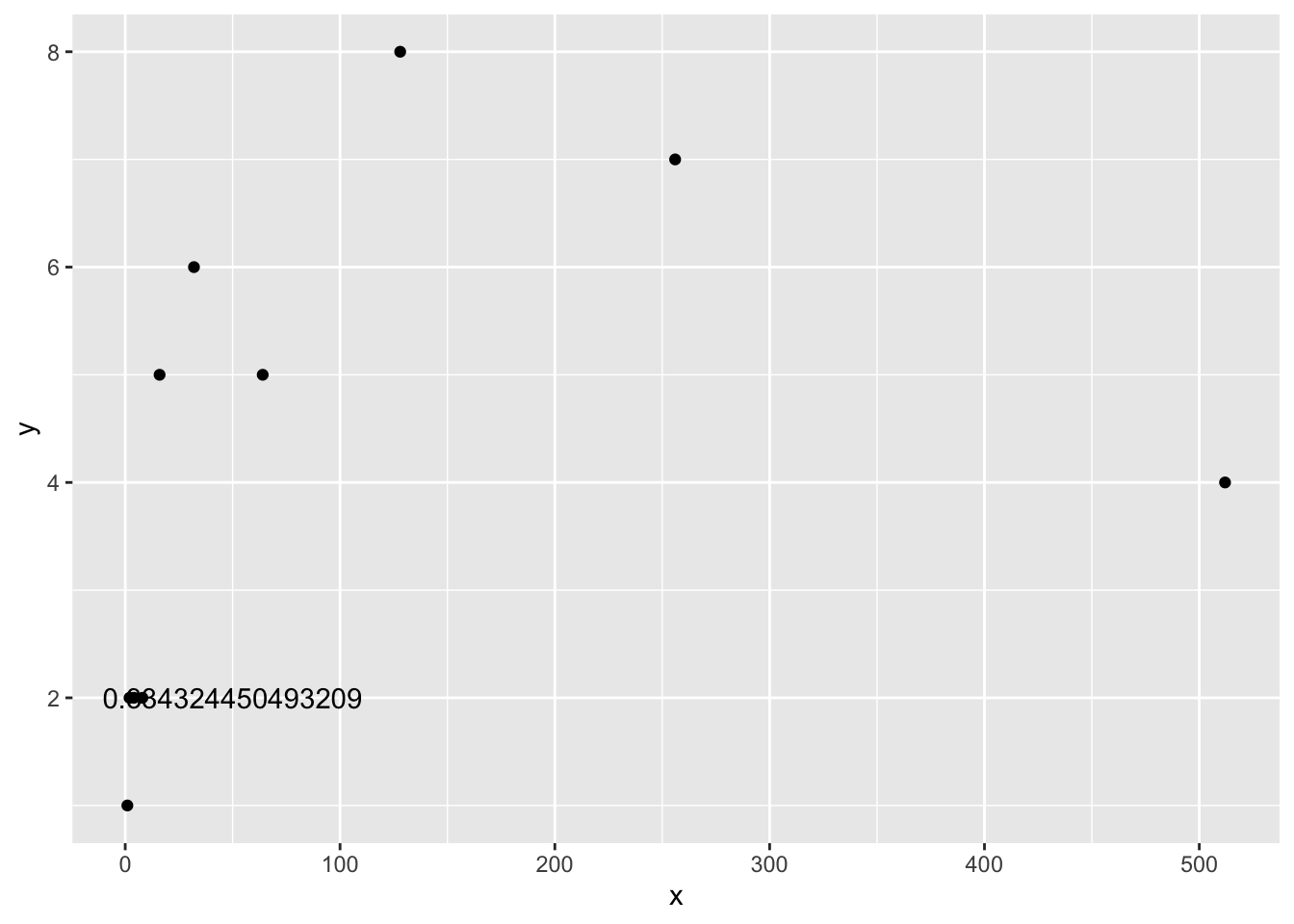
- Looking at the plot above, why is it probably not valid to summarise this data using Pearson’s \(r\)?
3.4 Real data
Let’s take a look at some correlations in real data. We are going to look at responses to a questionnaire about happiness that was sent around the world, from the World Happiness Report.
3.4.1 Load the data
We first load the data into a data.frame:
# If you haven't already, this will load the tidyverse library and data
library(tidyverse)
whr_data <- read_csv('data/WHR2018.csv')3.4.2 Look at the data
head(whr_data)
tail(whr_data)
glimpse(whr_data)You should be able to see that there is data for many different countries, across a few different years. There are lots of different kinds of measures, and each are given a name. You can find in the World Happiness Report what each of the measures represent. For now, I’ll show you some examples of asking questions about relationships between variables within this data, then you get to ask and answer your own question.
3.4.3 Example question #1
For the year 2017, does a countries measure for “Social support” correlate with that countries measure for “Healthy life expectancy at birth?”
Let’s find out. We make the scatter plot and then calculate the correlation. We did something similar in the textbook, so the following should look familiar to you:
ggplot(whr_data, aes(x=`Social support`,
y=`Healthy life expectancy at birth`))+
geom_point()+
theme_classic()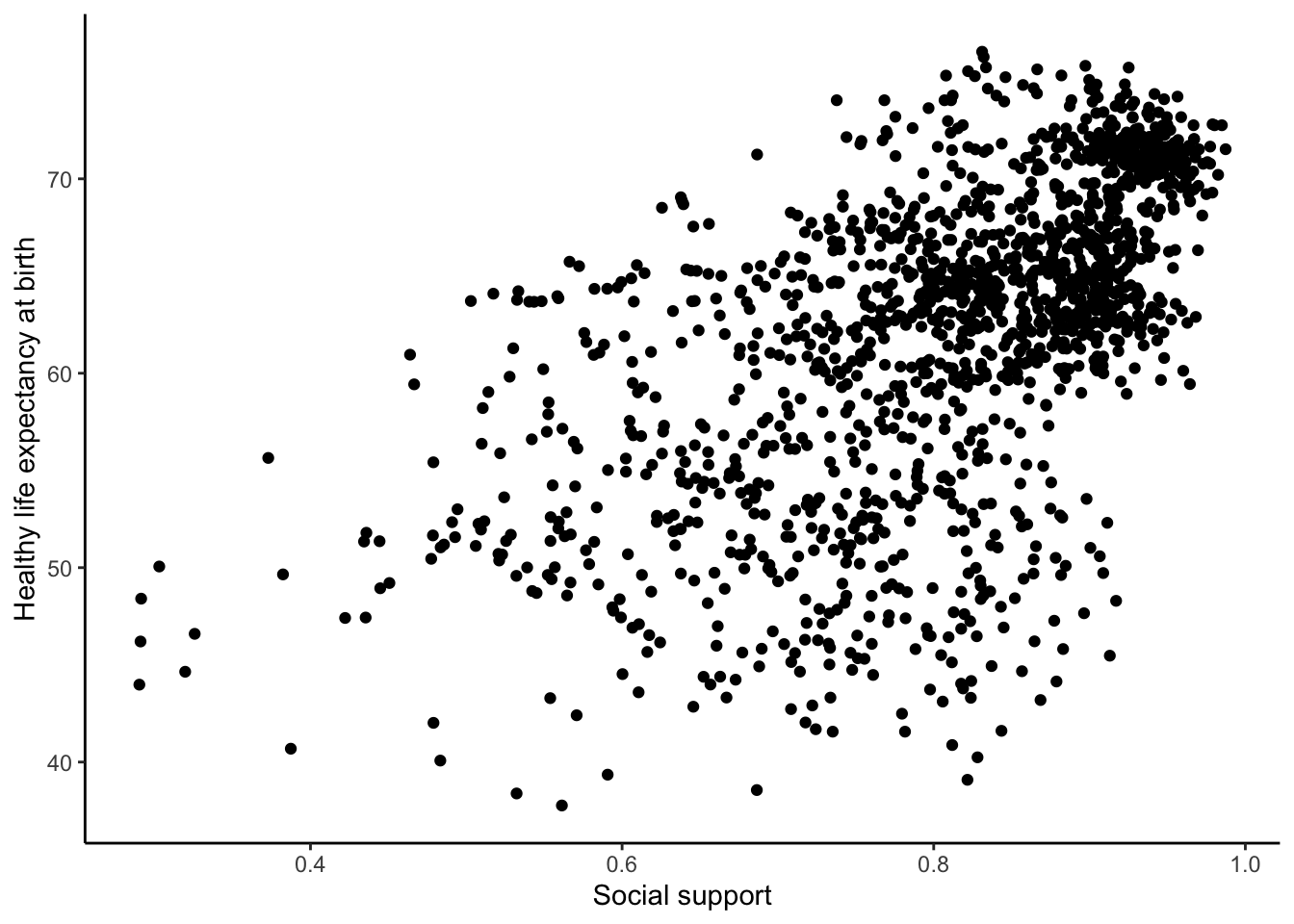
cor(whr_data$`Social support`,
whr_data$`Healthy life expectancy at birth`)## [1] NAWe see a lot of dots on the scatterplot, but the correlation has a value of NA (meaning undefined or not available). This occurred because there are some missing data points in the data and we can’t calculate a correlation over missing data. We should remove all the rows with missing data first (i.e. wrangle with our data), then calculate the correlation.
We do this in a couple of steps. First, we create our own data.frame with only the numbers we want to analyse. Then we select the columns we want to keep with select and use filter to remove the rows with NAs.
smaller_df <- whr_data %>%
select(country,
`Social support`,
`Healthy life expectancy at birth`) %>%
filter(!is.na(`Social support`),
!is.na(`Healthy life expectancy at birth`))
cor(smaller_df$`Social support`,
smaller_df$`Healthy life expectancy at birth`)## [1] 0.5867593Now we see the correlation is approximately 0.59. However, this is the correlation for all years in the dataset, not just 2017. So, we need to filter for the year 2017 as well:
smaller_df <- whr_data %>%
select(country,
`Social support`,
`Healthy life expectancy at birth`,
`year`) %>%
filter(`year` == 2017) %>%
filter(!is.na(`Social support`),
!is.na(`Healthy life expectancy at birth`))
ggplot(smaller_df, aes(x=`Social support`,
y=`Healthy life expectancy at birth`))+
geom_point()+
theme_classic()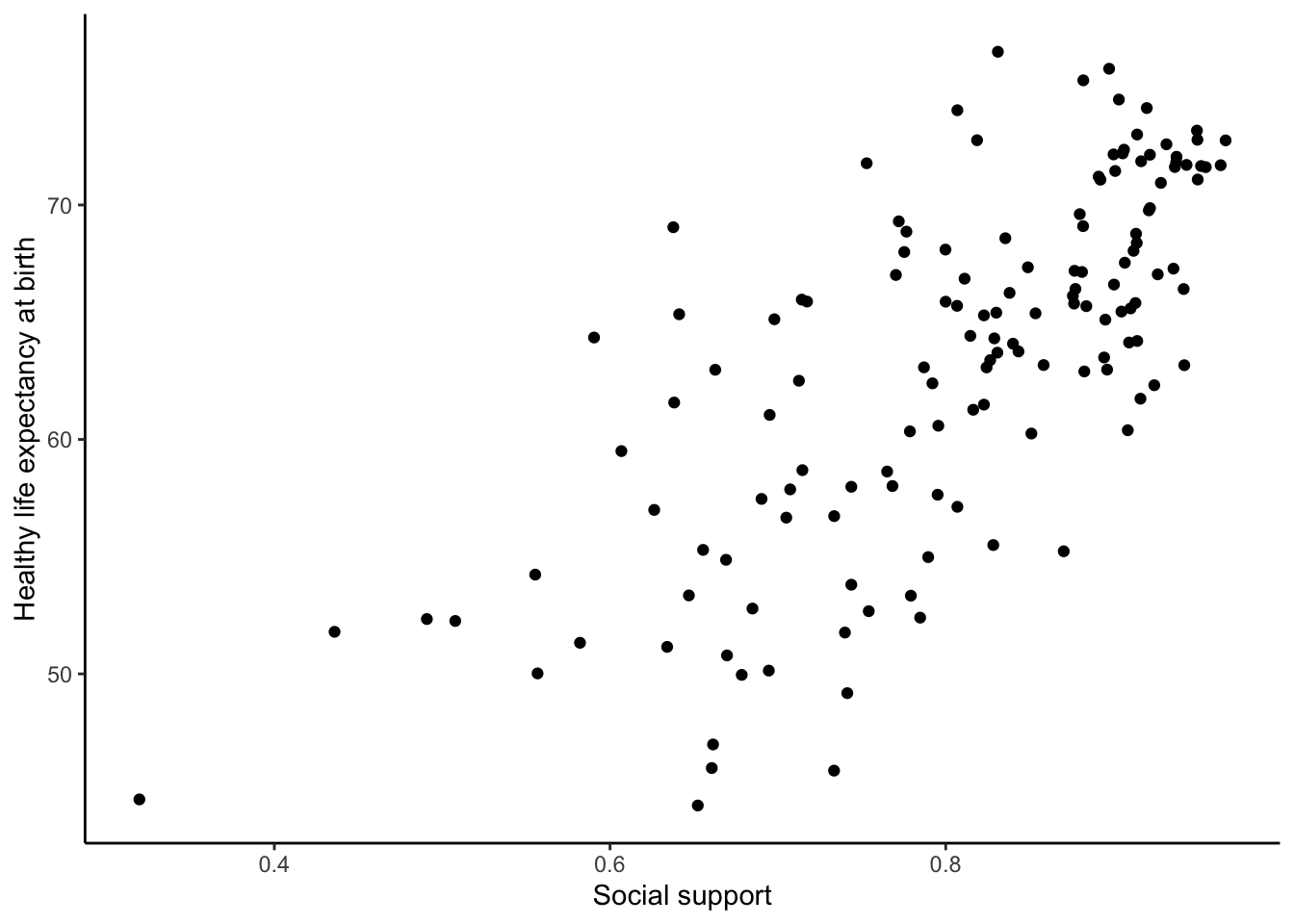
cor(smaller_df$`Social support`,
smaller_df$`Healthy life expectancy at birth`)## [1] 0.7200551Although the scatter plot shows the dots are everywhere, it generally shows as social support increases, life expectancy increases. Let’s add a best fit line, so the trend is more clear. We use the geom_smooth() function to do this. We can also annotate the correlation value on the graph and change the alpha value of the dots so they blend a bit:
# Select variables of interest and filter for NAs and year == 2017
smaller_df <- whr_data %>%
select(country,
`Social support`,
`Healthy life expectancy at birth`,
`year`) %>%
filter(`year` == 2017) %>%
filter(!is.na(`Social support`),
!is.na(`Healthy life expectancy at birth`))
# Calculate correlation
corxy <- cor(smaller_df$`Social support`,
smaller_df$`Healthy life expectancy at birth`)
# Plot the data with best fit line
ggplot(smaller_df, aes(x=`Social support`,
y=`Healthy life expectancy at birth`))+
geom_point(alpha=.5)+
geom_smooth(method=lm,se=FALSE)+
annotate("text",label=paste("Correlation:",round(corxy,2)), x=0.4,y=70) +
theme_classic()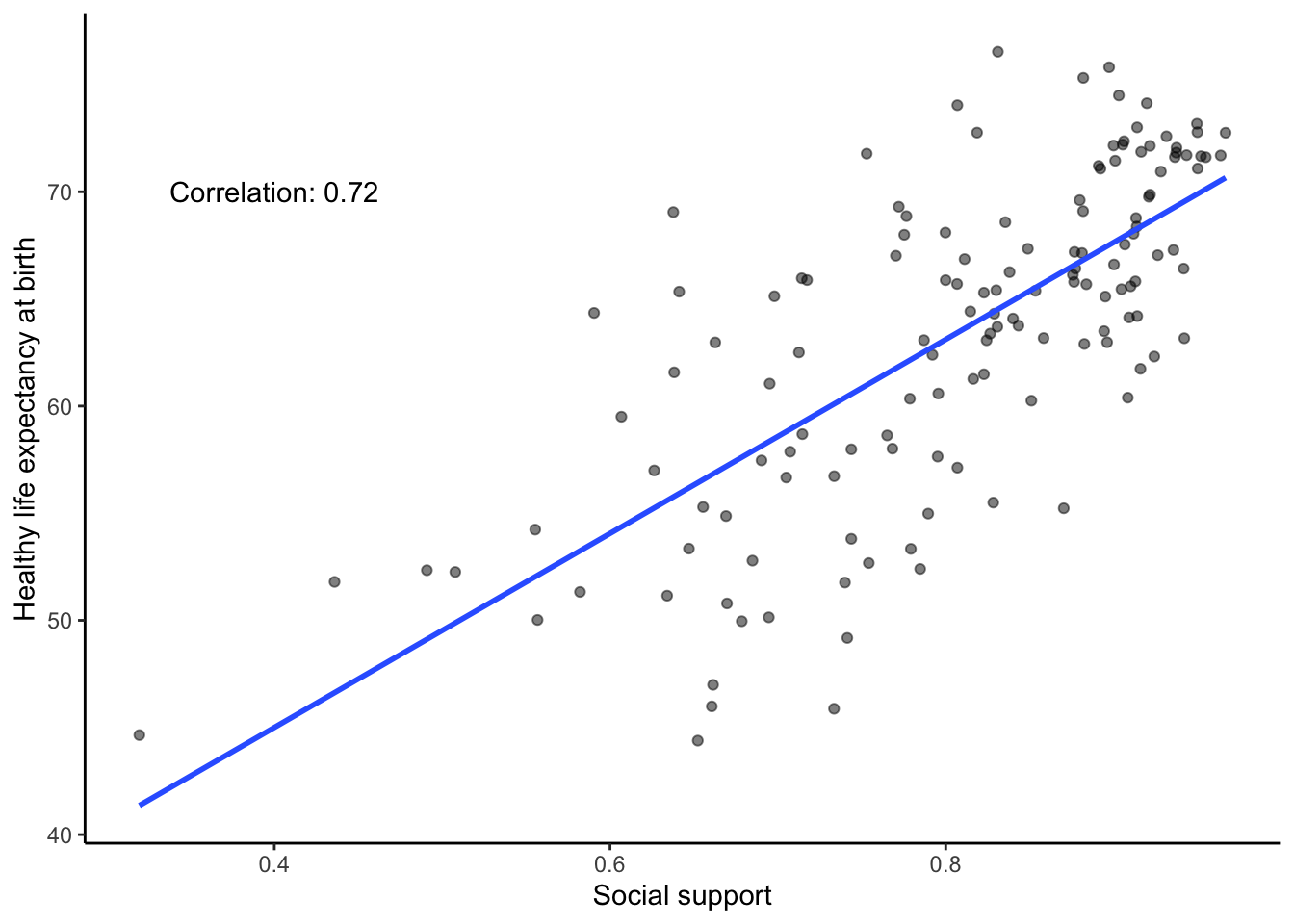
3.4.4 Example question #2
After all that work, we can now speedily answer more questions. For example, what is the relationship between positive affect in a country and negative affect in a country? I wouldn’t be surprised if there was a negative correlation here: when positive feelings generally go up, shouldn’t negative feelings generally go down?
To answer this question, we just copy paste the last code block, and change the variables to be Positive affect, and Negative affect:
# Select variables of interest and filter for NAs and year == 2017
smaller_df <- whr_data %>%
select(country,
`Positive affect`,
`Negative affect`,
`year`) %>%
filter(`year` == 2017) %>%
filter(!is.na(`Positive affect`),
!is.na(`Negative affect`))
# Calculate correlation
corxy <- cor(smaller_df$`Positive affect`,
smaller_df$`Negative affect`)
# Plot the data with best fit line
ggplot(smaller_df, aes(x=`Positive affect`,
y=`Negative affect`))+
geom_point(alpha=.5)+
geom_smooth(method=lm,se=FALSE)+
annotate("text",label=paste("Correlation:",round(corxy,2)), x=0.45,y=0.45) +
theme_classic()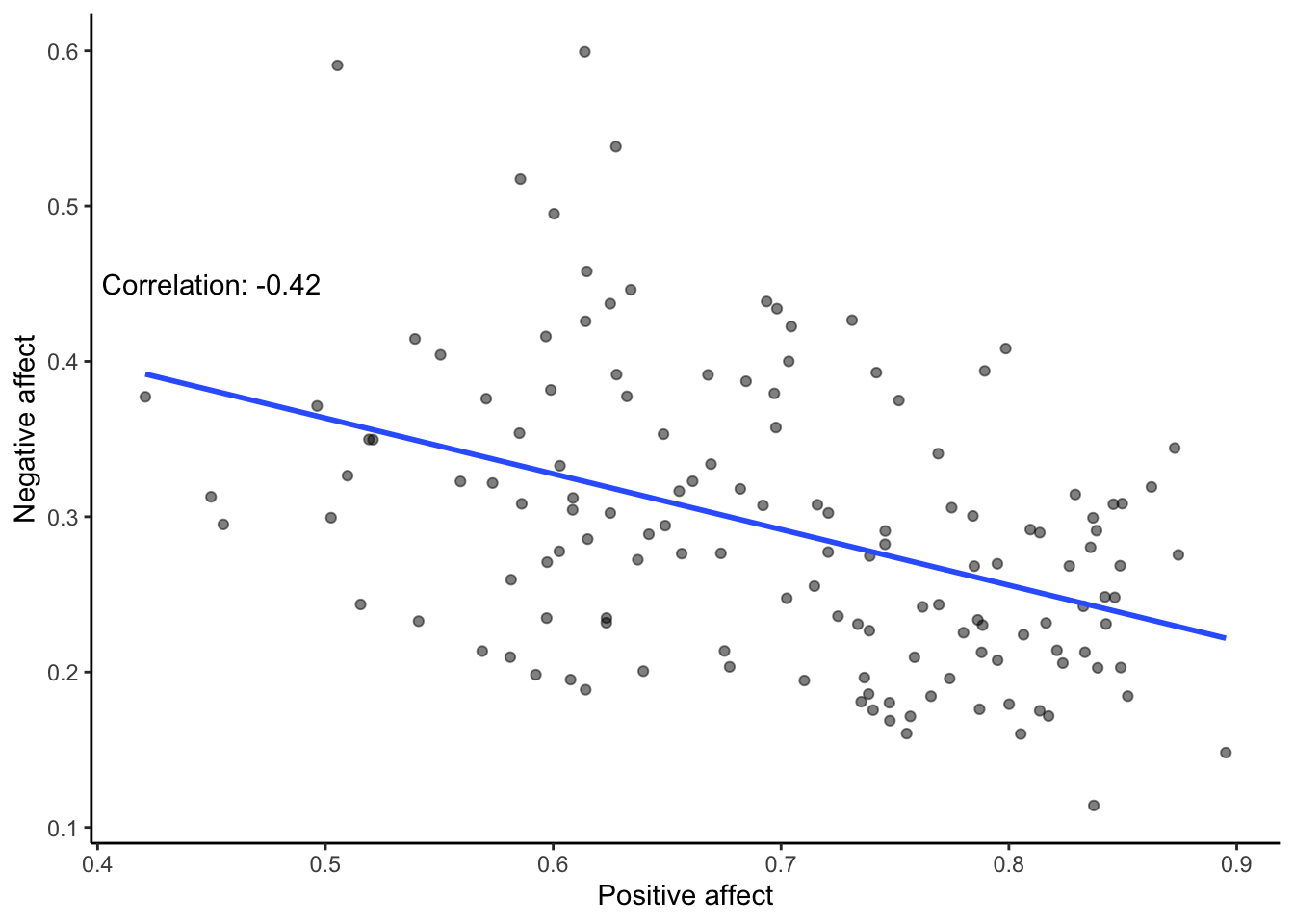
There we have it. As positive affect goes up, negative affect goes down. A negative correlation.
Complete the exercises below in your lab template.
3.4.5 Theory exercises
Answer the following questions in your own words:
- Explain the difference between a correlation of r = .3 and r = .7. What does a larger value of r represent?
- Explain the difference between a correlation of r = .5, and r = -.5.
3.4.6 Data exercise
You should have all tools available to answer your own question about a relationship in the WHR dataset. This should be a different relationship (and about a different year) than the examples above. You should calculate Pearson’s \(r\) of this relationship, generate a scatterplot with a best fit line, print the correlation on the scatterplot, and print the mean and standard deviation of both variables in a table. Your code should include all steps, from loading the relevant libraries and data file, to generating all the required output. Use comments throughout your code to explain what your are doing.
When you have completed all exercises and are happy with your progress today, please knit your lab template and submit it to Canvas. If you finish before the time is up, start with the required readings of Week 4, work on your assignment, or help out your fellow students.